Prometheus
Prometheus 受启发于 Google 的 Brogmon 监控系统(相似的 Kubernetes 是从 Google 的 Brog 系统演变而来),从 2012 年开始由前 Google 工程师在 Soundcloud 采用 Go 语言编写的开源软件,并且于 2015 年早期对外发布早期版本。到 2016 年 Prometheus 成为继 Kubernetes 之后,成为 CNCF 的第二个成员。
Prometheus的主要特点包括:
多维数据模型:使用键值对的方式组织数据,支持灵活的查询和聚合。
强大的查询语言:PromQL(Prometheus Query Language)允许用户对数据进行复杂的查询和计算。
自动化发现:支持多种服务发现机制,能够自动发现和监控新服务。
可视化:集成Grafana等可视化工具,提供丰富的仪表盘和图表展示。
Prometheus 架构如下图所示:
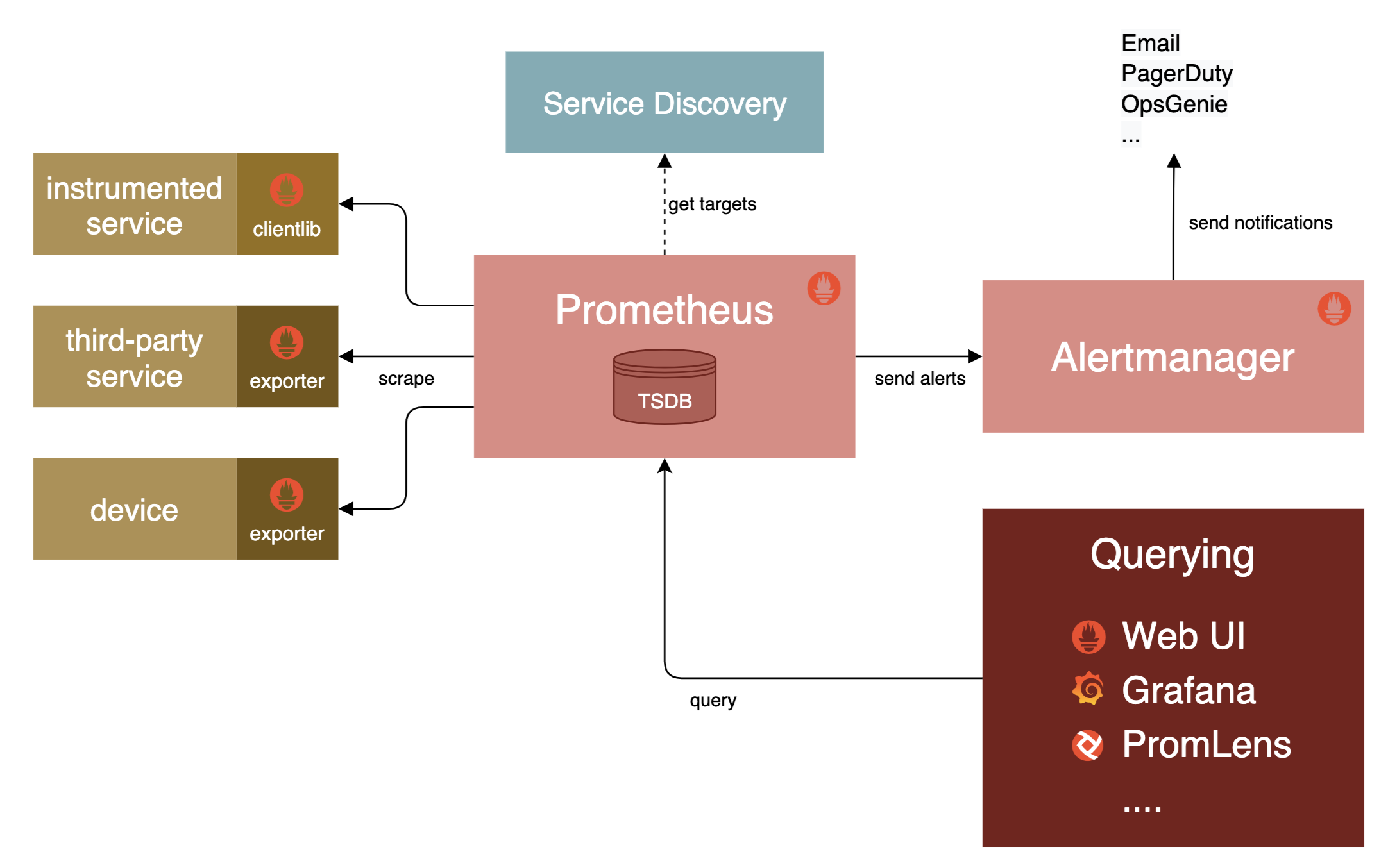
通常来说在监控系统中有两种方法可以获取监控指标:拉取式采集(Pull-Based Metrics Collection)和推送式采集(Push-Based Metrics Collection)。所谓 Pull 是指指标系统主动从目标系统中拉取指标,相对地,Push 就是由目标系统主动向指标系统推送指标。这两种方式并没有绝对的好坏优劣,以前很多老牌的指标度量系统,如 Ganglia、Graphite、StatsD 等是基于 Push 的,而以 Prometheus、Datadog、Collectd 为代表的系统则采取了 Pull 方式。Push 还是 Pull 的权衡,不仅仅在指标中才有,所有涉及客户端和服务端通讯的场景,都会涉及该谁主动的问题。
一般来说,指标系统只会支持其中一种指标采集方式,因为指标系统的网络连接数量,以及对应的线程或者协程数可能非常庞大,如何采集指标将直接影响到整个指标系统的架构设计。Prometheus 基于 Pull 架构的同时还能够有限度地兼容 Push 式采集,是因为它有 Push Gateway 的存在,如上图所示,这是一个位于 Prometheus Server 外部的相对独立的模块,将外部推送来的指标放到 Push Gateway 中暂存,然后再等候 Prometheus Server 从 Push Gateway 中去拉取,所以对于 Prometheus 本身而言只是 Pull 模式。Prometheus 设计 Push Gateway 的本意是为了解决 Pull 的一些固有缺陷,譬如目标系统位于内网,通过 NAT 访问外网,外网的 Prometheus 是无法主动连接目标系统的,这就只能由目标系统主动推送数据;又譬如某些小型短生命周期服务,可能还等不及 Prometheus 来拉取,服务就已经结束运行了,因此也只能由服务自己 Push 来保证度量的及时和准确。
Prometheus 只允许通过 HTTP 访问 metrics 端点这一种访问方式。如果目标提供了 HTTP 的 metrics 端点(如 Kubernetes、Etcd 等本身就带有 Prometheus 的 Client Library)就直接访问,否则就需要一个专门的 Exporter 来充当媒介。
Exporter 是 Prometheus 提出的概念,它是目标应用的代表,既可以独立运行,也可以与应用运行在同一个进程中,只要集成 Prometheus 的 Client Library 便可。Exporter 以 HTTP 协议返回符合 Prometheus 格式要求的文本数据给 Prometheus 服务器。现在社区中已经有大量各种用途的 Exporter(比如 MySQL、Redis、Kafka 等等),让 Prometheus 的监控范围几乎能涵盖所有用户所关心的目标,绝大多数用户都只需要针对自己系统业务方面的度量指标编写 Exporter 即可。
另外我们还可以配置 Prometheus 根据收集的指标数据生成报警,但是 Prometheus 不会直接把报警通知发送给我们,而是将原始报警转发到 Alertmanager 服务,Alertmanager 是作为单独的服务运行的,可以从多个 Prometheus 服务上接收报警,并可以对这些报警进行分组、汇总和路由,最后可以通过 Email、Slack、企业微信、Webhook 或其他通知服务来发送通知。